
Perfilando la memoria de lectura con SQLAlchemy
Entendiendo el uso de cursores en el cliente y el servidor

SQLAlchemy es la librería más usada para interactuar con bases de datos en Python. Pero trabajar con datos no es fácil! Estamos añadiendo una capa de dificultad externa al propio código y debemos conocer bien tanto los datos con los que estamos jugando como la plataforma en la que residen: la base de datos (DB).
Esta librería nos proporciona abstracciones que son realmente cómodas para que no tengamos que pensar demasiado qué pasa en el lado de la DB. Sacamos ciertos datos fuera, los mapeamos a objetos en Python y seguimos con nuestras vidas. Aun así, debemos ser capaces de elegir correctamente como interactuamos con el origen de los datos.
Uno de los puntos principales a tener en cuenta es administrar correctamente la memoria de nuestros procesos: Si trabajamos con muchos datos y los intentamos leer todos de golpe, seguramente acabemos con un Out of Memory Error, que se puede traducir en un error 137 (SIGKILL) si estamos trabajando en entornos containerizados.
En este post vamos a analizar tres estrategias diferentes, ver cuánta memoria consumen y como se comportan en el lado de la DB, leyendo siempre los mismos datos de la misma tabla origen.
Nota: Para el análisis vamos a usar una única tabla con 1M de registros en Postgres. Para el perfilado de la memoria, usaremos mprof.
all()
from sqlalchemy import create_engine, text
connection_string = "postgresql://demo:password@localhost:5432/postgres"
engine = create_engine(connection_string)
with engine.connect() as conn:
res = conn.execute(text("SELECT * FROM public.employees")).all()
counter = 0
for elem in res:
counter += 1
print(counter)Vamos a empezar con la forma más simple: Una única query a la tabla employees que va a intentar sacar el millón de registros de una sentada. El proceso corre deprisa, pero si miramos cuánta memoria nos estamos comiendo, llega por encima de los 600MB.
Esto no es necesariamente malo, sólo tenemos que entender los recursos que debemos proveer al servicio, o como se va a comportar si los datos evolucionan en el futuro.
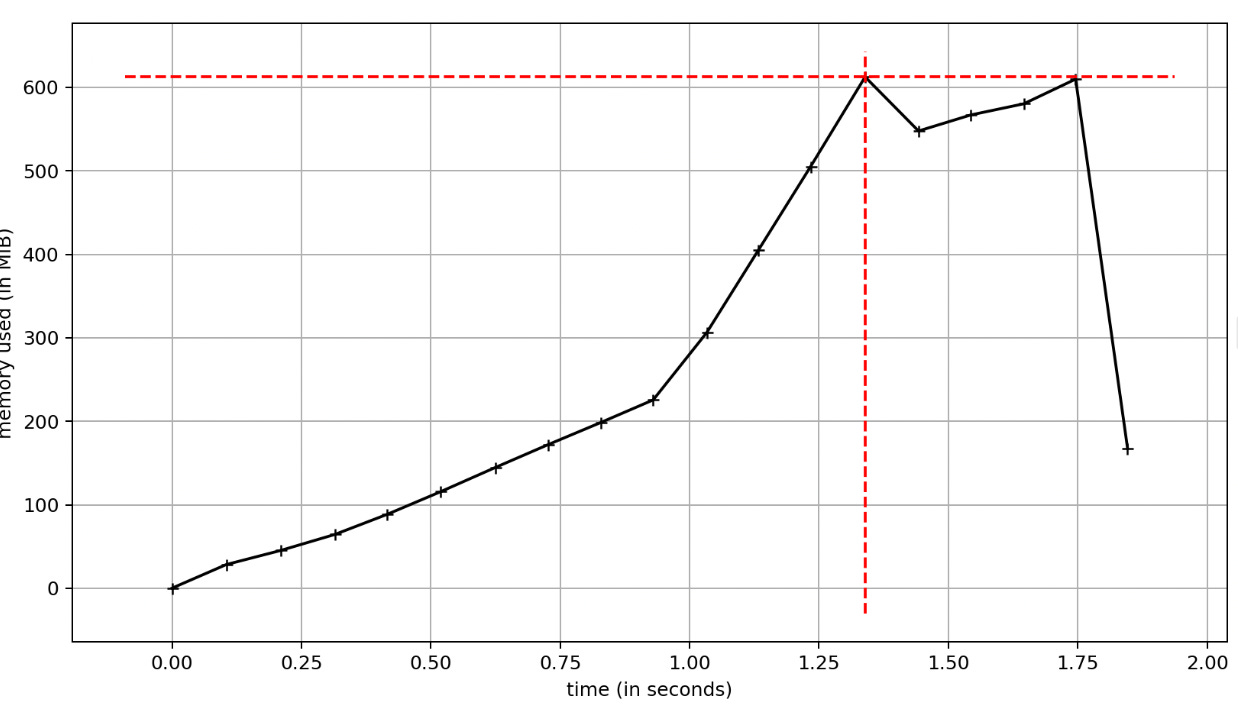
Entender como el cliente de Python gestiona este escenario está bien, pero es aún más interesante si entramos directamente en como la DB está respondiendo a nuestra llamada, con la siguiente query:
SELECT
u.usename,
stats.queryid,
stats.query,
stats.total_exec_time
FROM pg_stat_statements stats
join pg_catalog.pg_user u
on u.usesysid = stats.userid
where u.usename = 'demo';Aquí no debería ser una sorpresa ver una única entrada con la query SELECT * FROM public.employees. Estamos levantando un único Result de la DB equivalente a toda la tabla, e iteramos sobre este resultado directamente en el cliente.
Veamos si lo podemos hacer algo mejor.
yield_per()
with engine.connect() as conn:
res = conn.execute(text(
"SELECT * FROM public.employees"
)).yield_per(10)
counter = 0
for rows in res:
counter += 1
print(counter)Fijaos como ahora estamos llamando yield_per sobre el objeto que nos proporciona el execute(...).
Esto crea un cursor en el cliente con el siguiente perfil de memoria:
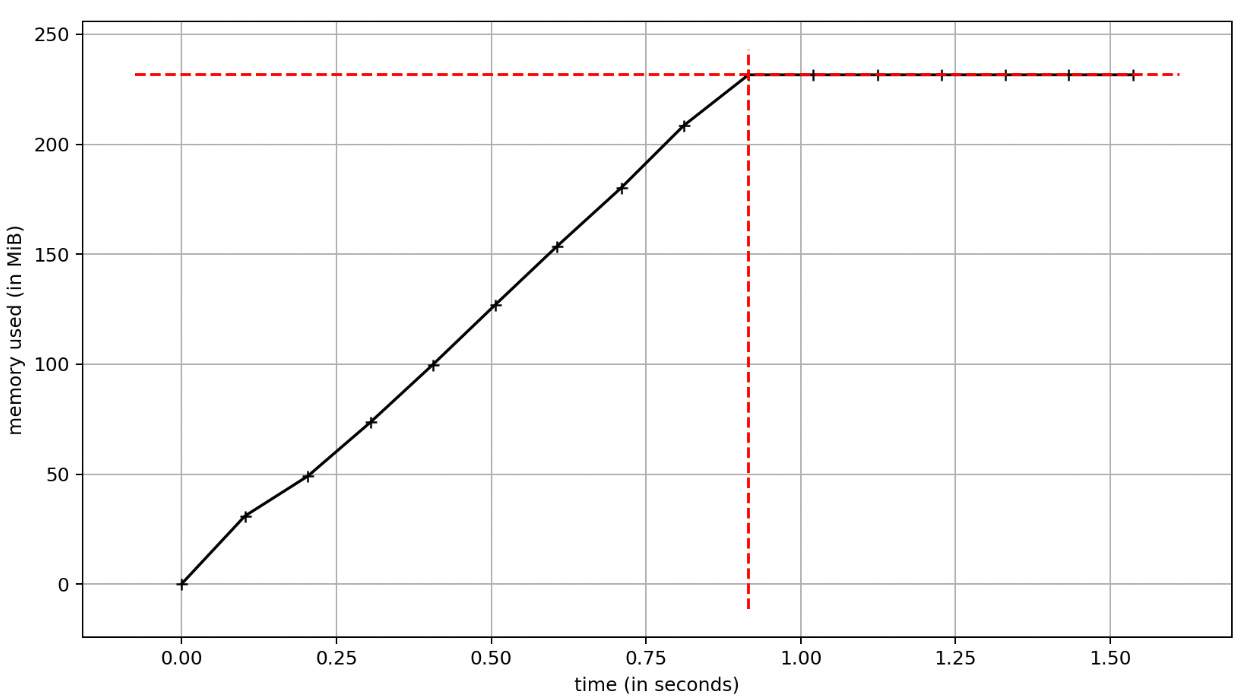
Ahora estamos justo por debajo de 250MB, bastante mejor que con la llamada a all(). Si revisamos de nuevo las entradas en pg_stats_statements, todavía veremos una única llamada a la query SELECT * FROM public.employees.
En este escenario seguimos haciendo una única llamada a la DB, pero estamos iterando sobre los datos de forma algo más eficiente del lado del cliente.
Todavía podemos hacerlo mejor.
Cursores en el servidor
Según la docu de Postgres: En lugar de ejecutar una consulta completa de una vez, es posible configurar un cursor que encapsule la consulta y luego leer el resultado unas pocas filas a la vez.
Esta sería una estrategia estupenda a seguir aquí. En vez de cargar toda la tabla employees, podríamos obtener unas pocas filas en cada llamada. Esto implica múltiples viajes a la DB, pero el uso de memoria será mucho menor.
Por suerte, SQLAlchemy nos permite hacer streams de resultados para usar directamente los cursores de las bases de datos. Iremos algo más lentos, pero la memoria del cliente no va a explotar.
with engine.connect() as conn:
result = conn.execution_options(stream_results=True, max_row_buffer=100).execute(
text("select * from public.employees")
)
counter = 0
for row in result:
counter += 1
print(counter)Vamos a preparar el execution_options antes de llamar a execute, tuneando la comunicación db <> cliente.
Esto nos deja un uso de memoria algo mayor a 40MB!
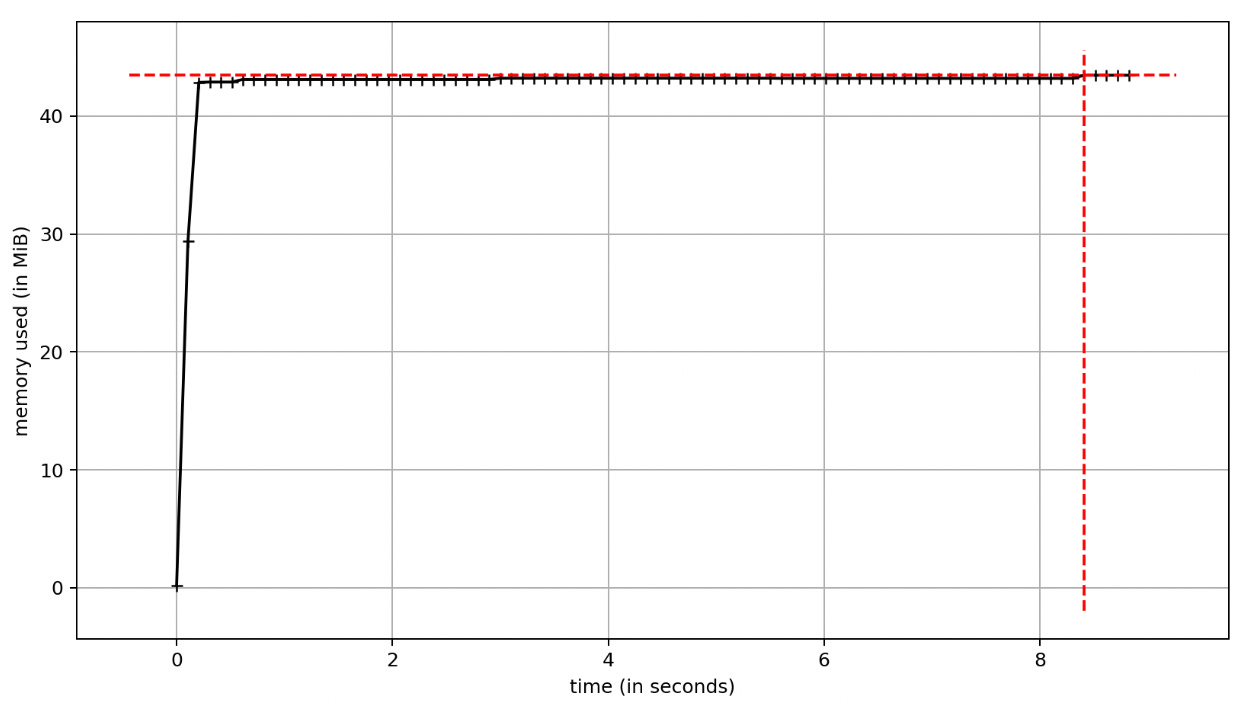
Si ahora revisamos las entradas en pg_stats_statements, veremos que realmente estamos levantando la tabla employees a trozos (en chunks):
DECLARE "c_10289e140_1" CURSOR WITHOUT HOLD FOR select * from public.employees
FETCH FORWARD 100 FROM "c_10289e140_1"
FETCH FORWARD 25 FROM "c_10289e140_1"
...Conclusión
Qué método deberíamos usar? Como siempre, depende: del tamaño de los datos, la velocidad que necesita el proceso, los recursos con los que contamos, etc. Lo importante es elegir con conocimiento de causa, una vez entendemos las diferencias de como nuestro proceso se va a comportar.
En el siguiente post, vamos a adentrarnos en cómo preparar el set de datos con el que hemos jugado de una manera supercómoda.
Un abrazo.